



In Oracle Database 19c, the Cost-Based Optimizer (CBO) selects the most efficient method to retrieve data. These methods are known as SQL access paths.
One of the fastest index access paths is the Index Unique Scan. It occurs when Oracle uses a unique index to retrieve exactly one row from a table.
Because the index guarantees uniqueness, Oracle can locate the required row immediately, making this access path extremely efficient.
1. What is an Index Unique Scan?
An Index Unique Scan happens when Oracle searches a unique index using a value that uniquely identifies a single row.
Typical cases include:
- Primary key
- Unique constraint
Example table:
CREATE TABLE employees (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
salary NUMBER
);
Oracle automatically creates a unique index on employee_id or we can specify the index name
CREATE TABLE employees (
employee_id NUMBER CONSTRAINT EMP_EMP_ID_PK PRIMARY KEY,
first_name VARCHAR2(50),
salary NUMBER
);
Example query:
SELECT *
FROM employees
WHERE employee_id = 120;
Since employee_id is unique, Oracle knows only one row can match, so it performs an Index Unique Scan.
2. Execution Plan Example
EXPLAIN PLAN SET statement_id = 'wadhah_sql_index_scan_unique' FOR select salary from employees where employee_id=120;
Example output:
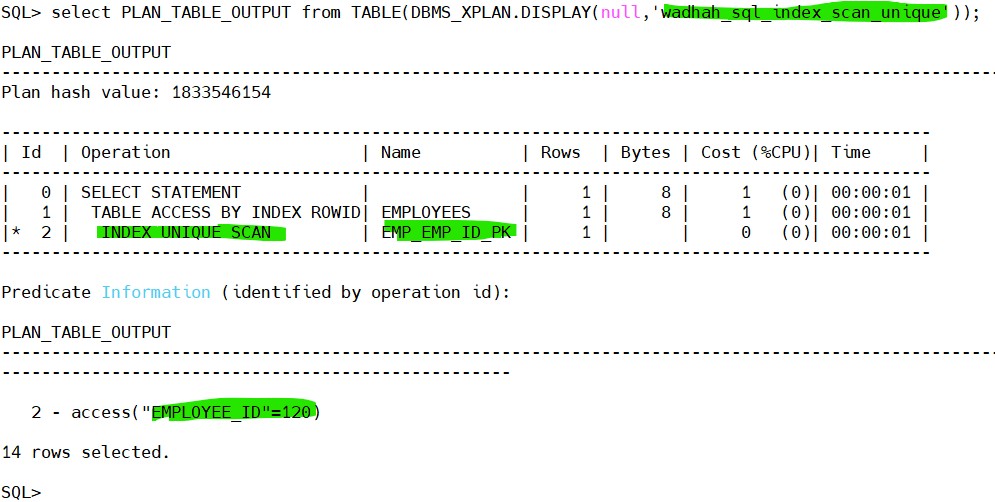
Explanation:
- Oracle searches the unique index.
- The index returns the ROWID.
- Oracle retrieves the row from the table using ROWID.
3. How Index Unique Scan Works
The process is very efficient:
- Oracle navigates the B-tree index structure
- It finds the exact index entry
- The index returns the ROWID
- Oracle retrieves the row from the table
Because only one entry is accessed, the operation is very fast.
4. When Oracle Uses Index Unique Scan
Oracle chooses this access path when:
- A unique index exists
- The query condition matches the entire unique key
- The condition uses equality (=)
5. Performance Characteristics
Index Unique Scan is one of the most efficient access paths because:
- Only one index entry is accessed
- Only one table row is retrieved
- Very low I/O cost
Typical I/O operations:
- 1 index block read
- 1 table block read
6. Best Practices
To benefit from Index Unique Scans:
- Define primary keys
- Use unique constraints
- Ensure queries use exact equality conditions








